

2025 começou com um verdadeiro tsunami no segmento da inteligência artificial. Após meses e meses falando sobre diferentes modelos e empresas como Google, Microsoft, Apple, Meta e, claro, OpenAI, uma empresa chinesa tirou da cartola a DeepSeek, uma IA que abalou os alicerces da indústria.
Mais do que suas capacidades ou o quão bem funcionava, o que realmente causou furor foram as questões econômicas e de hardware. Quase desde o início surgiu a pergunta: como a China conseguiu lançar do nada uma IA como a DeepSeek com as limitações de hardware impostas pela guerra comercial com os Estados Unidos e a impossibilidade de comprar as placas gráficas mais potentes da NVIDIA?
Para isso, a empresa afirmou ter recorrido à criatividade, utilizando uma infraestrutura baseada em chips H800 da Nvidia e realizando um treinamento de mais de 2,788 bilhões de horas a um custo ridiculamente baixo: 5,6 milhões de dólares. E parece pouco, considerando que a OpenAI investiu cerca de 100 milhões de dólares para treinar o GPT-4.
Outro assunto é quanto custa manter o DeepSeek. Como aponta a Reuters, se o ChatGPT custa cerca de 700 mil dólares por dia, a DeepSeek opera por apenas 87 mil dólares. E aqui entram alguns pontos importantes a considerar.
O DeepSeek é 10 vezes mais barato de manter que o ChatGPT, segundo a própria DeepSeek
Em março, como destaca a Reuters, a DeepSeek revelou alguns dados sobre os custos e receitas relacionados aos seus modelos V3 e R1. O primeiro é um chatbot tradicional, mais voltado para conversas, ideal para redação e criação de conteúdos. Já o R1 é um modelo de raciocínio. Ele se destaca na resolução de problemas, utiliza lógica e é capaz de apresentar um raciocínio passo a passo, além de se beneficiar de um aprendizado contínuo.
Para efeito de comparação com modelos mais conhecidos, o DeepSeek V3 seria equivalente ao GPT-4, enquanto o R1 se assemelha ao o1 da OpenAI. No relatório, a Reuters destaca que a relação teórica de custo-benefício da DeepSeek chega a até 545% por dia. Ainda assim, a própria empresa alerta que as receitas reais são significativamente menores.
Outro dado interessante revelado pela DeepSeek diz respeito ao custo de manutenção. Manter o ChatGPT em funcionamento custa cerca de 700 mil dólares por dia à OpenAI (pelo menos há dois anos). Isso se deve à necessidade de manter a infraestrutura de servidores Azure da Microsoft, ao alto consumo energético, aos salários dos funcionários e, claro, a toda a potência de hardware necessária para processar as consultas recebidas a cada segundo.
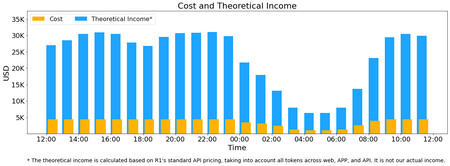 Em amarelo, os custos. Em azul, a renda teórica
Em amarelo, os custos. Em azul, a renda teórica
A DeepSeek paga “apenas” 87.072 dólares, um valor irrisório em comparação. Em março, a empresa afirmou que alugar as H800 custa menos de dois dólares por hora, e os rendimentos teóricos estimados giram em torno de 560 mil dólares, o que daria mais de 200 milhões de dólares por ano. No gráfico acima, a DeepSeek mostra o custo de manter o R1 e os rendimentos teóricos gerados pelos tokens processados, cujo preço varia conforme o horário do dia, sendo mais baratos à noite. Também é mencionado que o DeepSeek V3 é “significativamente mais barato”.
Isso levanta ainda mais questões. Uma delas é como pode ser tão barato, já que treinar uma IA certamente não é. Ignorando a acusação de roubo feita pela OpenAI, caso a DeepSeek não esteja inflacionando os números, ela mostra que talvez não seja necessária uma quantidade absurda de potência gráfica para treinar uma inteligência artificial.
A chave aqui é o reinforcement learning, a abordagem encontrada pela DeepSeek para fazer mais com muito menos. Mas também vale destacar que, embora os chips da NVIDIA sejam usados no treinamento do modelo R1, a inferência está sendo feita com os Ascend 910B da Huawei.
Os chips da Huawei são mais econômicos e, supostamente, mais eficientes, e essa decisão da DeepSeek é talvez ainda mais relevante do que o próprio custo de manter o sistema. O motivo é que ela pode ensinar outras empresas de inteligência artificial que talvez não valha a pena usar as GPUs de última geração para tudo, mas apenas para o treinamento — que ocorre em momentos pontuais, antes da implementação da IA — e, depois disso, empregar outras GPUs mais eficientes e baratas para a inferência. Essa inferência é o processo realizado posteriormente, num uso que poderíamos chamar de “real”.
O treinamento seria o equivalente a absorver manuais técnicos durante uma graduação de cinco anos, e a inferência algo como colocar esse conhecimento em prática e raciocinar com base no que foi aprendido, sem precisar reaprender tudo novamente. No fim das contas, a polêmica dos cinco milhões de dólares da DeepSeek ainda vai render discussões por um tempo, especialmente quando comparamos com os números da OpenAI, mas é evidente que a DeepSeek está adotando uma abordagem diferente e pode se tornar um bom exemplo para empresas que vierem depois.
E, com uma China fortemente empenhada no desenvolvimento tanto de IA quanto de hardware para IA, esse pode ser o modelo ideal para liderar o avanço nessa área.
Imagens | GitHub (DeepSeek), Xataka
Este texto foi traduzido/adaptado do site Xataka Espanha.
Ver 0 Comentários